tl;dr
Shrinkr lets you convert a folder’s worth of audio or video files by running a simple command on a build script:
scons -f ShrinkrTranscode -k
In other words, it’s a command-line batch transcoder with rework avoidance.
By default it’s set up to convert any .mp4 or .mkv files it finds in current directory and rescale them to Full HD resolution using ffmpeg.
You can edit the ShrinkrTranscode file to change parameters and selected input files, everything is under your control, since it is essentially a Python script with SCons’ declarative build extensions on top.
tl;dw
Setting It Up
You need to have the Python, SCons, and FFmpeg executables installed and discoverable via your system or user PATH environment variable.
Then, simply grab a copy of the ShrinkrTranscode file, put it in the folder with the files you want to transcode, and run it as above.
The Repository
All of the development files are located at https://github.com/nuket/Shrinkr.
The Long Version
A while back, before I was even starting to heavily use Shotcut for non-linear video editing, I wanted a way to automatically generate proxy editing files from original video files.
None of my computers have the hardware decoders necessary for HEVC video and I needed to resample the video down to a more manageable resolution.
So I wrote the original version of Shrinkr as a Python script that could take a JSON configuration file and convert an input video file into any number of output profiles (UtVideo, Huffyuv, and so on). I was basically reinventing the wheel, though.
I didn’t really ever use the original Shrinkr, as it would require also swapping the proxy files with those that the editing software would be using. This would require parsing in an XML project file, figuring out where all of the filenames were located in the object tree, rewriting them, and then writing that whole thing out.
Also, I had other things I wanted to work on. So I shelved it.
Fast forward several months: As of its 20.06.28 release, Shotcut has an integrated proxy editing workflow, which makes proxy file generation superfluous. This saves a ton of effort on the user’s part.
But what about regular transcoding? What options are available for batch transcoding there?
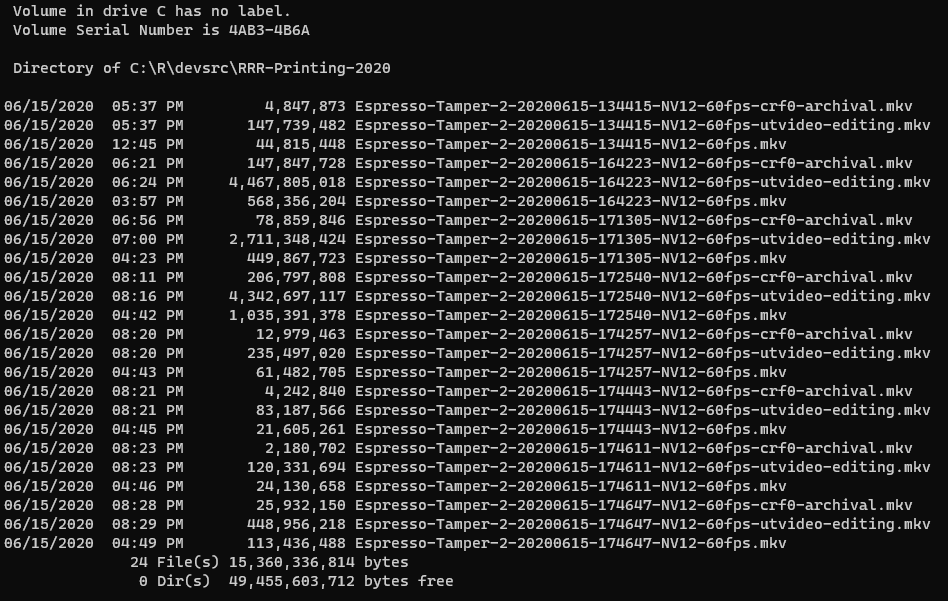
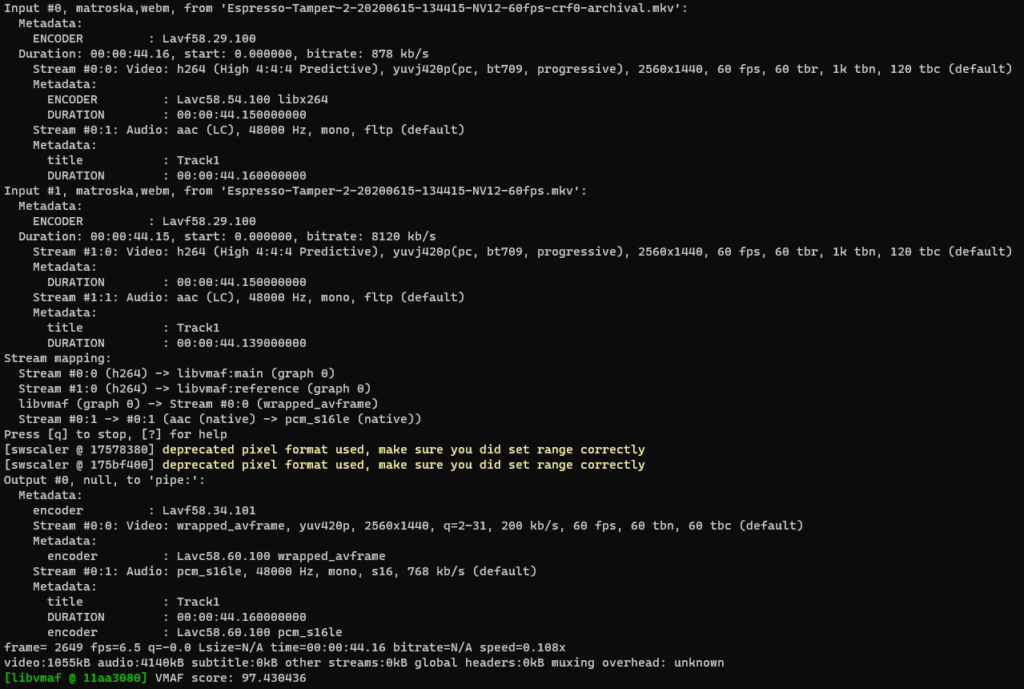
I had been archiving a number of screencast files recorded using Open Broadcast Software. These were recorded using ffmpeg‘s lossless x264 with whatever high bitrate it needed, but post processing the files for archival would often reduce the storage required by 66 – 75%.
So I wrote a new version of Shrinkr that essentially leverages the SCons build system to track which files need processing.
It is basically a build script, configurable however it is needed, using all of the power of the Python language.
This saves a ton of code, and gets right to the point:
Transcoding media files is conceptually identical to compiling software, so using a real build system makes sense.
Hope this helps anyone out there looking for a simple way to get their bulk transcoding done.